
آزمون نرمال بودن داده (normality test)، تعیین می کند که آیا یک داده نمونه از یک جمعیت حول میانگین جامعه توزیع شده است. معمولاً برای بررسی اینکه آیا داده های درگیر در تحقیق دارای توزیع نرمال هستند یا خیر انجام می شود. بسیاری از روش های آماری مانند همبستگی، رگرسیون، آزمون های t و ANOVA، MANCOVAیعنی آزمون های پارامتریک، بر اساس توزیع نرمال داده ها هستند. در نتیجه انجام آزمون نرمال بودن داده برای انتخاب آزمون های آماری لازم است.
توزیع نرمال که با نام توزیع گاوسی نیز شناخته می شود، مهمترین توزیع احتمال آماری برای متغیرهای تصادفی مستقل است. اکثر محققان آن را به عنوان منحنی زنگی شکل آشنا در گزارش های آماری می شناسند. توزیع نرمال برای متغیرهای پیوسته مناسب است. این یک توزیع احتمال است که نسبت به میانگین متقارن است، یعنی سمت راست تصویر آینهای سمت چپ است، که نشان میدهد دادههای نزدیک به میانگین بیشتر از دادههایی که از میانگین فاصله دارند، رخ میدهند. سطح زیر منحنی توزیع نرمال نشان دهنده احتمال است و مساحت کل زیر منحنی تا یک جمع می شود. در یک توزیع کاملا نرمال، مقادیر میانگین، میانه و حالت یکسان هستند و اوج منحنی را نشان می دهند. براساس شکل زیر آزمون نرمال بودن داده مثبت است.
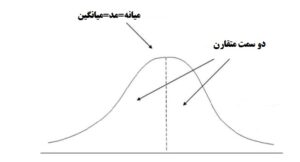
روشهای مختلفی برای ارزیابی اینکه آیا دادهها به طور نرمال توزیع شدهاند وجود دارد، و آنها در دو دسته کلی گرافیکی-مانند:
هیستوگرام، نمودار Q-Q
و تحلیلی- مانند
آزمون شاپیرو ویلک، آزمون کولموگروف اسمیرنوف قرار میگیرند.
این روش های آزمون نرمال بودن داده معمولا در نرم افزار SPSS اجرا می شوند.
ما با اساسی ترین فرآیند تجزیه و تحلیل داده ها شروع می کنیم. هنگام تجزیه و تحلیل داده ها، اطلاعات انبوه (ترکیب شده) از بسیاری از نقاط داده به دست می آید، بنابراین مهم است که چنین داده های انبوهی به طور صادقانه ارائه شود، یعنی به گونه ای که مجموعه داده را به بهترین شکل نشان دهد. داده هایی که به طور معمول توزیع شده اند، بهترین و به درستی از طریق میانگین و انحراف معیار نشان داده می شوند.
میانگین حسابی مقداری است که از جمع همه مقادیر و تقسیم آن بر تعداد مشاهدات به دست می آید و انحراف معیار اندازه گیری پراکندگی متغیر است (انحراف استاندارد پایین نشان دهنده پراکندگی کم است، یعنی گروه بندی حول میانگین. انحراف استاندارد بالا نشان دهنده پراکندگی زیاد است، به عنوان مثال، مقادیر اغلب در دم قرار دارند یا از مرکز یا میانگین فاصله دارند. در مقابل، مقادیر غیرعادی توزیع شده تمایل دارند با استفاده از این مقادیر به خوبی نمایش داده نشوند، اما تمایل دارند در محدوده میانی و بین چارکی بهتر منعکس شوند.
اولین قدمی که باید برای بررسی اینکه آیا توزیع متغیر از توزیع نرمال پیروی می کند انجام دهیم، انجام آزمون نرمال بودن داده است که معمولاً می توان با استفاده از برخی از تست های استاندارد آزمون نرمال بودن داده که بخشی از اکثر برنامه ها و برنامه های آماری هستند، مانند آزمون های کولموگروف-اسمیرنوف، شاپیرو-ویلک و داگوستینو-پیرسون. این آزمون ها داده ها را تجزیه و تحلیل می کنند تا بررسی کنند که آیا توزیع آنها به طور قابل توجهی از توزیع نرمال انحراف دارد با استفاده از چندین پارامتر، مانند مقدار p-مشخص. اگر مقدار p <0.05 باشد، توزیع به طور قابل توجهی از توزیع نرمال منحرف می شود.
آزمون های پارامتریک زمانی استفاده می شوند که توزیع از توزیع نرمال پیروی کند. در غیر این صورت از آزمون های ناپارامتریک استفاده می شود. در نتیجه جواب مثبت یا منفی آزمون نرمال بودن داده حائز اهمیت است.
برای دو گروه از داده ها، پرکاربردترین آزمون پارامتریک آزمون t است (برای نمونه های مستقل یا زوجی، بسته به داده های ما) و معادل ناپارامتریک آن آزمون من ویتنی است. برای بیش از دو گروه داده، آزمون پارامتریک مورد استفاده ANOVA و معادل ناپارامتریک آن آزمون کروسکال-والیس است.
برای همبستگی، آزمون پارامتریک استفاده شده، آزمون همبستگی پیرسون و معادل ناپارامتریک آن، آزمون همبستگی رتبه ای اسپیرمن است.
توجه به این نکته مهم است که استفاده از آزمون اشتباه (به عنوان مثال، پارامتریک برای دادههای غیرعادی توزیع شده یا ناپارامتریک برای دادههای توزیع شده عادی) میتواند به یافتههای کاملاً اشتباه منجر شود. این ممکن است به اشتباه یافته های آماری معنی دار را به عنوان یافته های غیر معنی دار یا غیر معنی دار به عنوان یافته های آماری معنی دار نشان دهد! در نتیجه در ابتدای انتخاب آزمون های آماری، آزمون نرمال بودن داده انجام می شود.
به طور مشابه، هنگام انجام یک تحلیل رگرسیون، مهم است که به خاطر داشته باشید که توزیع نرمال داده ها یک فرض مهم برای انجام صحیح اکثر انواع تحلیل رگرسیون است. به عبارت دیگر، انجام اکثر اشکال رگرسیون با متغیرهای غیرعادی توزیع شده ممکن نیست. این متغیرها ممکن است باید به طریقی تبدیل شوند (به عنوان مثال، تبدیل log، تبدیل ریشه، و غیره) تا اطمینان حاصل شود که یک متغیر تبدیل شده به طور معمول توزیع شده است. این اغلب هنگام انجام تجزیه و تحلیل های آماری نادیده گرفته می شود و ممکن است به یافته های اشتباه منجر شود.




{kind=link}