
مدل های فراتحلیل مبتی بر اثرات ثابت و اثرات تصادفی هستند. معیار انتخاب مدل مناسب در فراتحلیل آزمون های ناهمگونی هستند. انتخاب کدام مدل در انجام فراتحلیل مهم است. اگر آزمون ناهمگونی معنادار بود و نشان داد که مطالعات حاضر در فراتحلیل از جهات مختلف مانند آزموندی، شیوه نمونه گیری، طرح تحقیق و … ناهمگون و متفاوت هستند از مدل اثرات تصادفی و در غیر این صورت از مدل اثرات ثابت استفاده می شود.
در مدل اثرات ثابت، فرض ما بر این است که یک اندازه اثر واقعی برای همه مطالعات وجود دارد و تفاوت مشاهده شده در اندازه اثرات به دلیل خطای نمونه گیری است. برخی اوقات مدل اثرات ثابت، مدل اثرت ثابت مشترک نامیده می شود. اما در مدل اثرات تصادفی، ما اجازه می دهیم که اندازه اثرات واقعی، از مطالعه ای تا مطالعه دیگر متفاوت باشد. برای مثال اندازه اثر می تواند به دلیل ویژگی های نمونه بالا و پایین برود. بنابراین نمی توان گفت که اختلاف در آزمودنی و شیوه اجرای مداخلات منجر به اندازه اثرات مختلف در مطالعات گوناگون می شود.
در مدل های اثرات تصادفی برخلاف مدل های اثرات ثابت، فرض بر این است که توزیعی از اندازه های اثر وجود دارد و تفاوت های اندازه های اثر میان مطالعات ، به تنهایی ناشی از خطای نمونه برداری نیست بلکه ناشی از عامل های دیگری مانند خطای اندازه گیری و تفاوت های ذاتی بین مطالعات است.
در مدل اثرات ثابت (Fixed Effect) فرض بر این است که همه مطالعات در فراتحلیل دارای یک اندازه اثر مشترک واقعی هستند. از طرف دیگر، همه اثرات موثر بر اندازه اثر در همه مطالعات مشترک هستند. بنابراین اندازه اثر واقعی در همه مطالعات یکی هستند. به اندازه واقعی، تتا گفته می شود.
دل «اثرات ثابت» ، میانگین وزنی یک سری از برآوردهای مطالعه را ارائه میدهد. معکوس واریانس تخمینها معمولاً به عنوان وزن مطالعه مورد استفاده قرار میگیرد، به طوری که مطالعات با حجم نمونهای بزرگتر تمایل دارند بیشتری از مطالعات با حجم کوچکتر در میانگین وزنی نقش داشته باشند. در نتیجه، هنگامی که مطالعات در یک فرا تحلیل توسط یک مطالعه با حجم نمونه بزرگ همراه میشود عملا نقش مطالعات با حجم کوچکتر را کمرنگ کرده یا از بین میبرد.
از همه مهمتر این که در مدل اثرات ثابت فرض میشود که همه مطالعات مربوط به یک جمعیت، از متغیر و تعاریف یکسانی استفاده میکنند. در حالیک ه به عنوان مثال اثرات درمانی ممکن است با توجه به محل، میزان دوز دارو، شرایط مطالعه و … متفاوت باشد. در عمل اثرات عوامل تصادفی در نظر گرفته نشده است.
مدل رایج مورد استفاده در ترکیب تحقیق و مطالعات ناهمگن، مدل «اثرات تصادفی» (Random Effect) فرا تحلیل است. همان گونه که بیان شد، مدل اثرات ثابت همه مطالعات یکی هستند. این فرض در همه تحقیقات ترکیبی برقرار نمی شود. وقتی ما تصمیم به ترکیب گروهی از مطالعات در یک فراتحلیل می گیریم، به طور حتم به مقدار کافی دارای اشتراک هستند که وارد تحقیقات ترکیبی شده اند. ولی هیچ دلیلی برای این وجود ندارد که اندازه اثرات واقعی در همه مطالعات دقیقا یکی باشد.
البته در این حالت هم از یک میانگین وزنی اندازه اثرات گروههای مطالعات استفاده میشود. وزنی که در این فرآیند برای هر تحقیق در محاسبه میانگین وزنی در فرا تحلیل با اثر تصادفی اعمال میشود، طی دو مرحله بدست میآید:
مرحله ۱: وزندهی با معکوس واریانس
مرحله ۲: وزندهی با استفاده از «مؤلفه واریانس اثر تصادفی» (Random Effects Variance Component) یا به اختصار REVC که به سادگی از میزان تغییرپذیری اندازه اثرات مطالعات مورد نظر، حاصل میشود.
این بدان معنی است که هر چه این اختلاف در اندازههای اثر بیشتر باشد، عدم وزنیدهی بیشتر شده و این این امر در نتیجه به میانگینگیری بدون وزن منجر میشود. در حالت دیگر، هنگامی که تمام اندازههای اثر مشابه باشند یا تغییرپذیری از خطای نمونهگیری تجاوز نمیکند، هیچ REVC استفاده نشده و فرا تحلیل اثرات تصادفی به سادگی پیش فرض فرا تحلیل اثرات ثابت را نتیجه میدهد و فقط به وزندهی با معکوس واریانس اکتفا میشود.
در مطالعه سیستماتیک به طور عام و در فراتحلیل به طور خاص، تحقیقات با سوال مشترک برای تحلیل جمع آوری می شوند. این تحقیقات با وجود داشتن سوالات مشترک، ممکن است از نظر طرح تحقیقات، آزمودنی مداخله، نوع نمونه گیری، شیوه تجزیه و تحلیل دارای تفاوت هایی باشند. ناهمگونی آماری زمانی وجود دارد که اندازه اثرات واقعی بین مطالعات متفاوت ارزیابی می شوند و بین نتایج تحقیقات و فرآیندهای انجام آن گوناگونی وجود داشته باشد.
وسعت این تغییرات تنها به دو عامل بستگی دارد:
۱-ناهمگونی در دقت یا «خطای نمونهگیری» (Sampling Error)
۲-ناهمگونی در اندازه اثر (Effect Size)
ارزیابی ناهمگونی در فراتحلیل به این دلیل اهمیت دارد که وجود یا عدم وجود ناهمگونی واقعی می تواند بر مدل های آماری؛ که محقق درباره به کارگیری آن در داده های خود تصمیم می گیرد، موثر باشد. بنابراین وقتی که نتایج مطالعات فقط برحسب خطای نمونه گیری متفاوت باشد، یک مدل اثرات ثابت باید برای دستیابی به میانگین اندازه اثرات به کار رود. برعکس اگر نتایج مطالعات بیشتر برحسب واریانس بین مطالعات متفاوت باشد، محقق باید از مدل اثرات تصادفی استفاده کند.
از آنجا که هیچ یک از این عوامل به طور خودکار نشانگر اشکال در یک مطالعه بزرگ یا مطلوبیت یا قابلیت اطمینان بیشتر در یک مطالعه کوچکتر نیستند، توزیع مجدد وزنها، تحت مدل اثرات تصادفی، هیچ ارتباطی با آنچه که این مطالعات در واقع ارائه میدهند، ندارد. آنچه مهم است، نمایش توزیع مجدد وزنها از مطالعات با حجم بزرگتر به کوچکتر است. به صورت معکوس افزایش مییابد، زیرا با این کار ناهمگنی افزایش مییابد تا اینکه در نهایت همه مطالعات دارای وزن برابر شده و توزیع مجدد جدیدی امکان پذیر نیست.
آزمون های بررسی ناهمگونی در مطالعات عبارتند از:
۱-آزمون Q: در صورتی که نتایج آزمون Q معنادار بود، فرض ناهمگونی مطالعات تایید می شود و باید از مدل اثرات تصادفی استفاده کرد. اما اگر این آزمون معنادار نبود، فرض ناهمگونی مطالعات رد می شود و باید از مدل اثرات ثابت استفاده کرد.
۲-واریانس بین مطالعات یا آزمون t2
۳-آزمون I2: وقتی این آزمون برابر صفر شود، به این معنا است که همه ناهمگونی های مشاهده شده در اندازه اثرات به خاطر خطای نمونه گیری است. به طور کلی مقادیر این آزمون اگر برابر ۰.۲۵، ۰.۵ و ۰.۰۷۵ باشد، به ترتیب به عنوان همگونی های پایین، متوسط و بالا تفسیر می شوند.
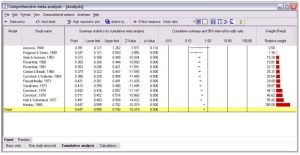
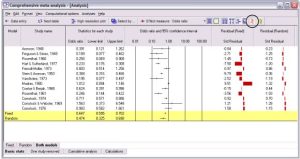
در نرم افزار CMA، بعد از وارد کردن داده های خام، گزینه Run Analysis اجرا می شود. در این خروجی مواردی همچون ضریب همبستگی، حد بالا و پایین، نمره استاندارد و سطح معناداری برای هر مطالعه گزارش شده است.
www.meta-analysis-workshops.com





{kind=link}