")
پانل دیتا (Panel Data) داده هایی حاوی مشاهدات از پدیدههای چندگانه بدستآمده در طول چندین دوره زمانی برای عناصر مشابه هستند. پانل دیتا ترکیبی از رگرسیون و سری زمانی. مدل ها از لحاظ استفاده از اطلاعات آماری به سه گروه تقسیم می شوند. داده های پانلی در نرم افزارهای حسابداری و مالی مانند eviews تحلیل می شوند. برخی از مدل ها با استفاده از «اطلاعات سری زمانی» یا به عبارتی طی دوره نسبتاً طولانی چند ساله برآورد می شوند. بعضی دیگر از مدل ها بر اساس «داده های مقطعی» برآورد می شوند یعنی متغیرها در یک دوره زمانی معین مثلاً یک هفته، یک ماه یا یک سال در واحدهای مختلف بررسی می شوند.
روش سوم برآورد مدل، برآورد بر اساس «داده های پانل» است. در این روش یک سری واحدهای مقطعی (مثلاً شرکت ها) در طی چند سال مورد توجه قرار می گیرند. با کمک این روش که در مطالعات سال های اخیر نیز زیاد استفاده شده است تعداد مشاهدات تا حد مطلوب افزایش می یابد. با توجه به اینکه مشاهده های ادغام شده باعث تغییرپذیری بالاتر، هم خطی چندگانه کمتر میان متغیرهای توضیحی، درجه آزادی بیشتر و کارآیی بالاتر تخمین کننده ها می شود، مطالعات پانل نسبت به مطالعات مقطعی و سری زمانی دارای مزیت است.
با توجه به توضیحات قسمت قبل می توان مزایای زیر را برای مدل های پانل دیتا (Panel Data)معرفی کرد:
دادههای پانل حاوی مشاهدات از پدیدههای چندگانه بدستآمده در طول چندین دوره زمانی برای عناصر مشابه هستند. پانل دیتا ترکیبی از رگرسیون و سری زمانی.
در حالت کلی مدل زیر نشان دهنده یک مدل با داده های پانل می باشد:
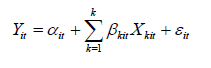
که در آن i=1,..n نشانگر واحدهای مقطعی (مثلا شرکت ها) و t نشانگر زمان است. برای برآورد مدل بر اساس داده های پانل روش های مختلفی همچون روش اثرات ثابت و روش اثرات تصادفی وجود دارد که بر حسب مورد، کاربرد خواهند داشت.
در روش اثرات ثابت فرض بر این است که ضرایب مربوط به متغیرها (شیب ها) ثابت هستند و اختلافات بین واحدها را می توان به صورت تفاوت عرض از مبداء نشان داد. در این حالت اگر عرض از مبداء تنها برای واحدهای مختلف مقطعی متفاوت باشد اصلاحاً روش اثرات ثابت یکطرفه نامیده شده و مدل آن بصورت زیر می باشد:
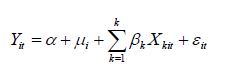
و اگر عرض از مبداء هم مابین مقاطع و هم مابین دوره ها متفاوت باشد روش اثرات ثابت دوطرفه نامیده می شود و مدل آن بصورت زیر خواهد بود:
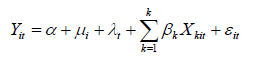
برای برآورد روش اثرات ثابت از مدل حداقل مربعات متغیر مجازی (LSDV) استفاده می شود. مدل اخیر یک مدل رگرسیونی کلاسیک بوده و هیچ شرط جدیدی برای تجزیه و تحلیل آن لازم نیست و از طریق روش حداقل مربعات معمولی قابل برآورد می باشد.
مدل های اثرات ثابت تنها درصورتی منطقی خواهد بود که ما اطمینان داشته باشیم که اختلاف بین مقاطع را می توان به صورت انتقال تابع رگرسیون نشان داد، در حالیکه ما همیشه از وجود این موضوع مطمئن نیستیم. برای رفع این مشکل روشی پیشنهاد شده است که به مدل اجزاء خطا یا اثرات تصادفی معروف است. این روش فرض می کند که جزء ثابت مشخص کننده مقاطع مختلف به صورت تصادفی بین واحدها و مقاطع توزیع شده است. بنابراین مدل اثرات تصادفی را می توان بصورت زیر تعریف کرد:
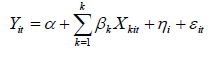
با توجه به اینکه در این حالت واریانس های مربوط به مقاطع مختلف با هم یکسان نیستند لذا مدل دچار ناهمسانی واریانس بوده و از روش حداقل مربعات تعمیم یافته (GLS) جهت برآورد مدل استفاده می شود.
برای آموزش پانل دیتا بر روی لینک زیر کلیک نمایید.





{kind=link}